From Imitation to Alignment:
Human-Preference Flow Policies for
Long-Horizon Sidewalk Navigation
Honglin He , Zhizheng Liu , Yukai Ma , Bolei Zhou
University of California, Los Angeles
TL;DR
- FlowPilot is a mapless, monocular-camera navigation policy that goes from imitation to alignment. We first pretrain the policy on large-scale offline demonstrations, then align it with only a few human-preference samples for safe, socially compliant behavior required by long-horizon sidewalk navigation.
1. 🌊 We introduce Anchored Flow Matching with gated conditioning to provide an expressive, multi-modal action representation that captures diverse sidewalk behaviors while suppressing goal-driven shortcuts.
2. 🤝 We propose a reward-free human-in-the-loop preference learning scheme that aligns the policy with socially compliant behavior from a small amount of human intervention data, while preserving imitation priors.
3. 🛣️ We validate in both simulation and real-world experiments: FlowPilot-Base reaches 42% success rate and 66% route completion in simulation, and human-preference fine-tuned FlowPilot-HP cuts the real-world intervention rate by 40.0% and normalized intervention rate by 52.1%.
FlowPilot Model Architecture
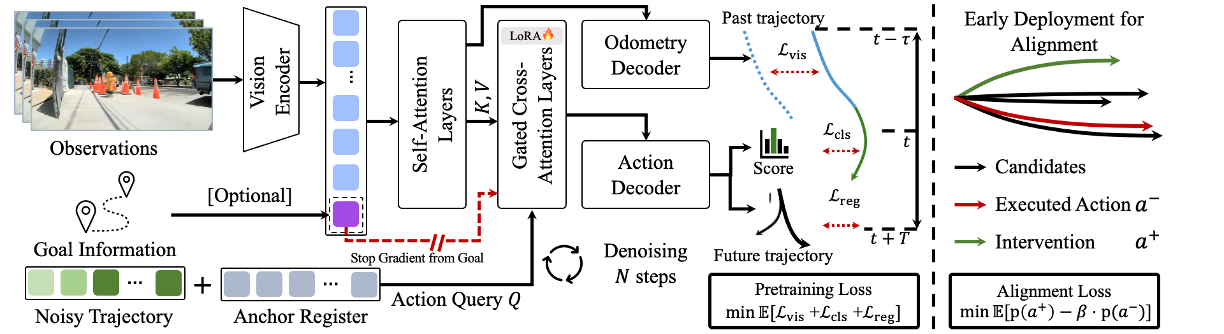
FlowPilot consists of two key components:
(1) Anchored Flow Matching: A conditional flow-matching policy anchored to clustered prototypical behaviors, learning smooth, multi-modal trajectories from offline demonstrations, with gated cross-attention that grounds decisions in scene context and avoids goal-driven shortcuts.
(2) Human-Preference Alignment: A reward-free, human-in-the-loop scheme that fine-tunes the pretrained policy from corrective interventions toward safe, socially compliant behavior while preserving the imitation prior.
Long-Horizon Sidewalk Navigation Results
Long-horizon results in real-world sidewalk environments: using only a monocular RGB camera and coarse GPS, FlowPilot stays on the walkway while avoiding obstacles and pedestrians.
Capability Demonstrations
All videos in this section are played at 6× speed.
Sidewalk Lane Keeping
FlowPilot keeps the robot centered on the sidewalk, smoothly following the walkable path through curves and intersections while staying clear of the road and grass margins.
Obstacle Avoidance
FlowPilot detects obstacles ahead like parked scooters and steers smoothly around them before returning to the sidewalk, without stalling or veering into the road.
Pedestrian Awareness
When pedestrians share or cross the walkway, FlowPilot anticipates their motion and responds in a socially compliant way: slowing, yielding, and keeping a safe clearance.
Robustness under Varying Lighting
At night, headlight glare, streetlamp halos, deep shadows, and low contrast severely degrade monocular RGB perception. Without any depth sensor, LiDAR, or pre-built map, FlowPilot still follows the sidewalk and avoids obstacles and pedestrians, holding stable trajectories across these challenging illumination conditions.
Comparison with State-of-the-Art Methods
NoMaD
FlowPilot-HP
CityWalker
FlowPilot-HP
Under identical conditions, FlowPilot-HP stays centered on the walkway and progresses smoothly toward the goal, while the NoMaD and CityWalker baselines drift off the sidewalk or stall.
Cross-Embodiment Generalization
FlowPilot generalizes across robot embodiments: the same policy controls robots with different dynamics, footprints, and camera viewpoints, maintaining consistent behaviors.
Ablation Studies
Effectiveness of Robot-Agnostic Pretraining
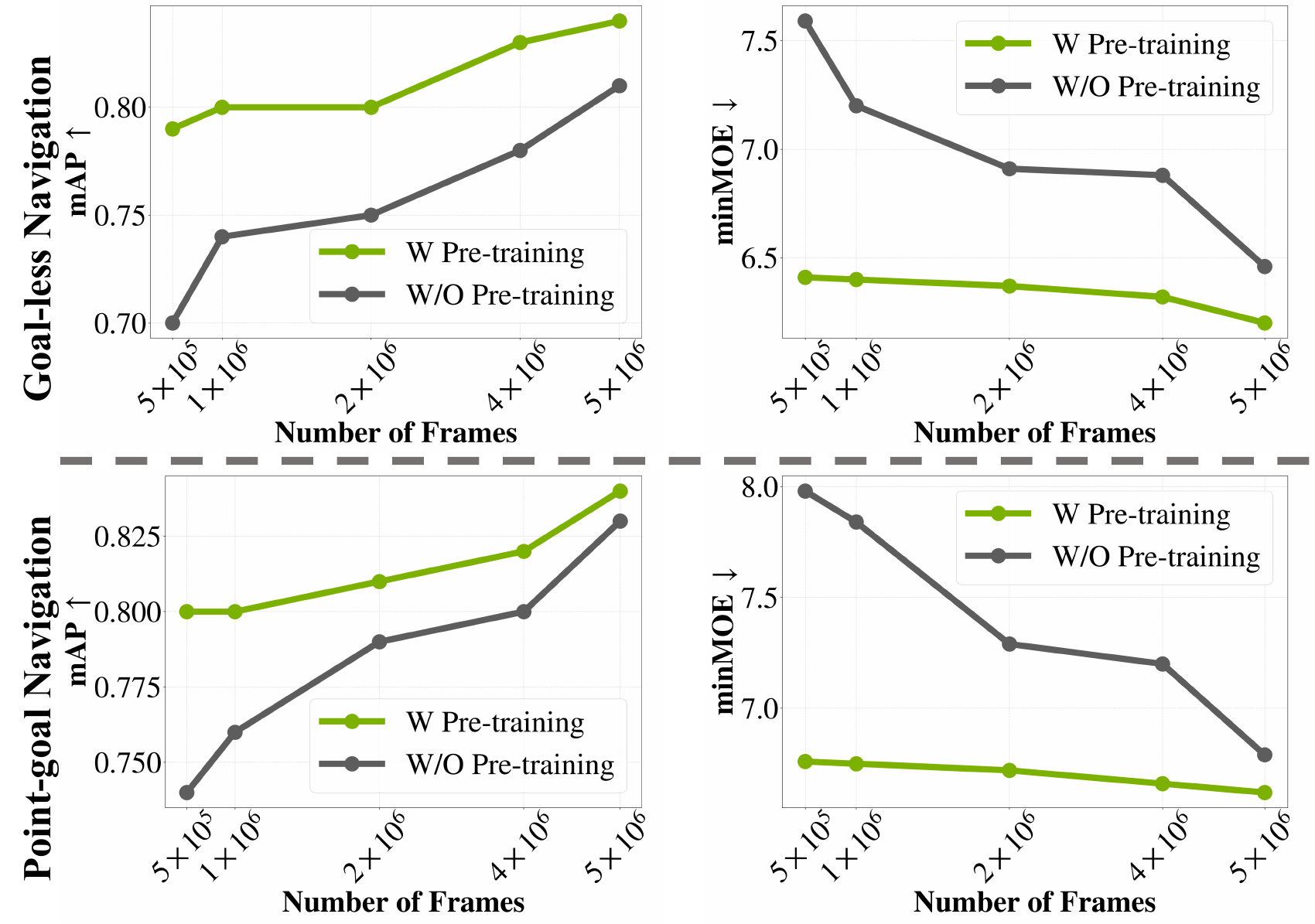
Pretraining on the large-scale robot-agnostic dataset with diverse dynamics improves downstream navigation for both goal-less and point-goal navigation, showing that robot-agnostic dataset is an effective, scalable pretraining signal.
Effectiveness of Gated Attention
Fraction of attention placed on the goal token across decoder layers. Without gating, attention increasingly concentrates on the goal (an attention sink) that encourages goal-driven shortcuts; gated attention markedly reduces this concentration in both mean and max, letting the policy attend to scene context.
Effectiveness of Preference Learning
Preference Data Collection-1
Preference Data Collection-2
FlowPilot-Base (Collision)
FlowPilot-HP (Success)
Top: preference data is gathered from brief human interventions during teleoperation. Bottom: starting from the same imitation prior, the preference-aligned FlowPilot-HP behaves more cautiously and is more socially compliant than FlowPilot-Base, requiring fewer interventions while retaining the base policy's navigation skills.
Reference
@article{he2026from,
title={From Imitation to Alignment: Human-Preference Flow Policies for Long-Horizon Sidewalk Navigation},
author={He, Honglin and Liu, Zhizheng and Ma, Yukai and Zhou, Bolei},
journal={arXiv preprint},
year={2026},
}
Acknowledgement
We thank Brad Squicciarini and Akshat Pandya for providing comments and feedback.