BridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
BridgeSim is a unified cross-simulator platform designed to evaluate OL pretrained E2E driving policies within high-fidelity CL environments in the MetaDrive simulator. BridgeSim designs a Furthermore, BridgeSim offers a flexible deployment setting to simulate open-loop policy with varying execution frequencies and simulation horizons, providing the functional depth necessary for systematic and rigorous diagnosis of OL-CL gap. Consequently, BridgeSim bridges the critical divide between open-loop benchmarks limited to short-term static prediction and existing closed-loop frameworks that often lack the comprehensive functionality and annotations required for complex, reactive stress-testing.
![]() Unified structural framework on low-level control for policy transfer to maintain state-action compatibility across domains
Unified structural framework on low-level control for policy transfer to maintain state-action compatibility across domains
![]() Unified scenario protocol to incorporate diverse map scenarios (e.g., nuPlan, WOMD, and nuScenes) with heterogeneous traffic modes (e.g., log-replay, IDM and adversarial policies) to stress-test E2E driving policies under closed-loop simulation environment.
Unified scenario protocol to incorporate diverse map scenarios (e.g., nuPlan, WOMD, and nuScenes) with heterogeneous traffic modes (e.g., log-replay, IDM and adversarial policies) to stress-test E2E driving policies under closed-loop simulation environment.
![]() Unified open-loop and closed-loop simulation modes and metrics for comprehensive evaluations.
Unified open-loop and closed-loop simulation modes and metrics for comprehensive evaluations.
Abstract
End-to-end autonomous driving has seen rapid progress on non-reactive simulation benchmarks such as NAVSIM, where planners are evaluated on PDMS-based metrics without environmental feedback. Yet gains on these open-loop (OL) metrics do not reliably transfer to closed-loop (CL) deployment, and the field continues to optimize for open-loop improvements. In this paper, we systematically decompose the root causes of this OL–CL deployment gap into two key factors: Information Asymmetry, resulting from observational domain shifts, and Objective Mismatch, driven by train-test optimization misalignment. Through principled analysis, we demonstrate that while Information Asymmetry is largely recoverable with standard adaptation, the primary catalyst for performance collapse is Objective Mismatch, specifically, biased Q-value estimates that fail to account for the reactive nature of the environment. We further show that under this mismatch, improving open-loop accuracy or scaling test-time computation over the open-loop objective yields diminishing or negative closed-loop returns. To this end, we propose a Test-Time Adaptation (TTA) framework that mitigates observational shift and debiases action-value estimates in inference time. Extensive experiments show that TTA effectively mitigates these biases and exhibits more favorable scaling dynamics than its baseline counterparts. Given these findings, we suggest the community reassess the prevailing reliance on non-reactive evaluation in driving research, and move toward closed-loop-aligned training and evaluation objectives that account for the interactive nature of real-world driving.
Decomposing OL-CL Gap
We define E2E policy as:
The root causes of the OL-CL deployment gap are decomposed into two key factors:
- Information Asymmetry occurs when there exists an observational domain shift and the source policy receives collapsed partially observable states in the target simulator.
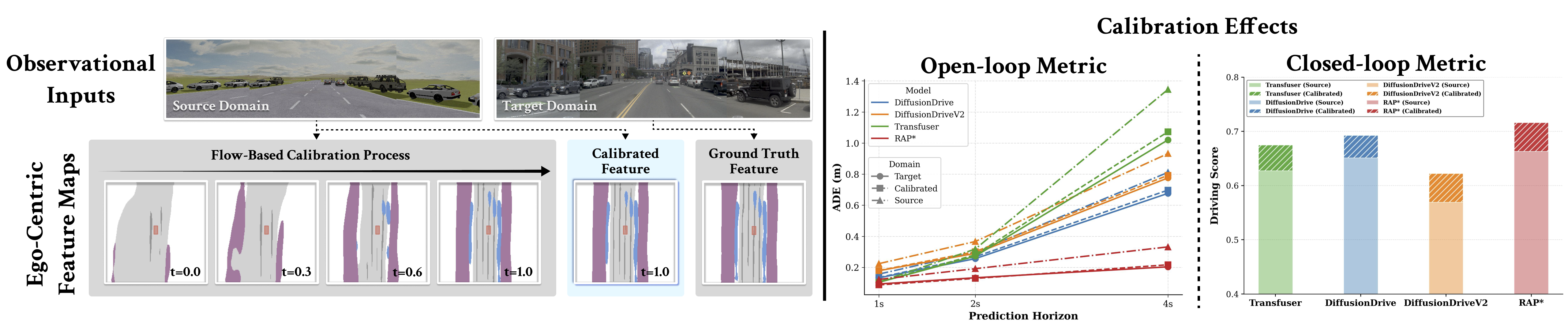
- Objective Mismatch occurs when OL policies, which is optimized against OL proxy reward during the training time, encounters the CL objective that the learned Q-function gives deviated estimates of true state-action values.
Test-time Adaptation (TTA) Framework
We propose a test-time adaptation (TTA) framework to improve closed-loop robustness of pretrained E2E policies without retraining, consisting of an Observational Calibrator and a Test-time Policy Adaptation procedure.
Observational Calibrator
Source and target domains induce different latent distributions due to domain-dependent sensing, causing the pretrained policy to receive out-of-distribution representations. We use flow matching to learn a transport map that aligns the source latent distribution to the target, mapping source observations into representations compatible with the downstream policy and effectively recovering open-loop performance.
Test-time Policy Adaptation
Unbiased Q-value Estimation
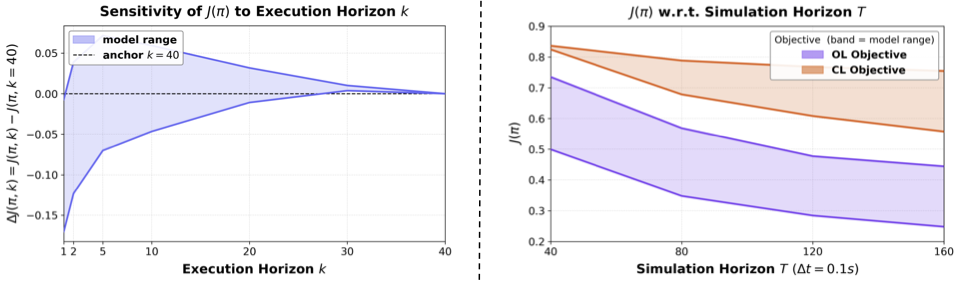
Standard Q-value estimation accumulates rewards infinitely, making it intractable under an open-loop model beyond the planning horizon $H$. We introduce a truncated action-value estimator that explicitly cancels the infinite tail:
At each step, the agent selects the candidate trajectory maximizing $\hat{Q}^{\pi}$, dynamically filtering out plans suffering from biased open-loop estimation.
Adaptive Replan
Standard test-time scorers operate memorylessly, selecting from the current candidate set at every step and causing action chattering. Instead, we carry forward the unexecuted remainder of the previous plan and retain it unless a new candidate yields a strictly higher estimated return, promoting temporal consistency and reducing unnecessary replanning across consecutive decision steps.